本文将介绍什么是SVM
SVM是什么?
SVM: support vector machine,俗称支持向量机。是一种二分类模型,其模型定义为特征空间上的间隔最大的线性分类器,策略就是间隔最大化,最终转化为一个凸二次规划问题的求解。感觉已经晕了,下图给出一些intuition的部分:
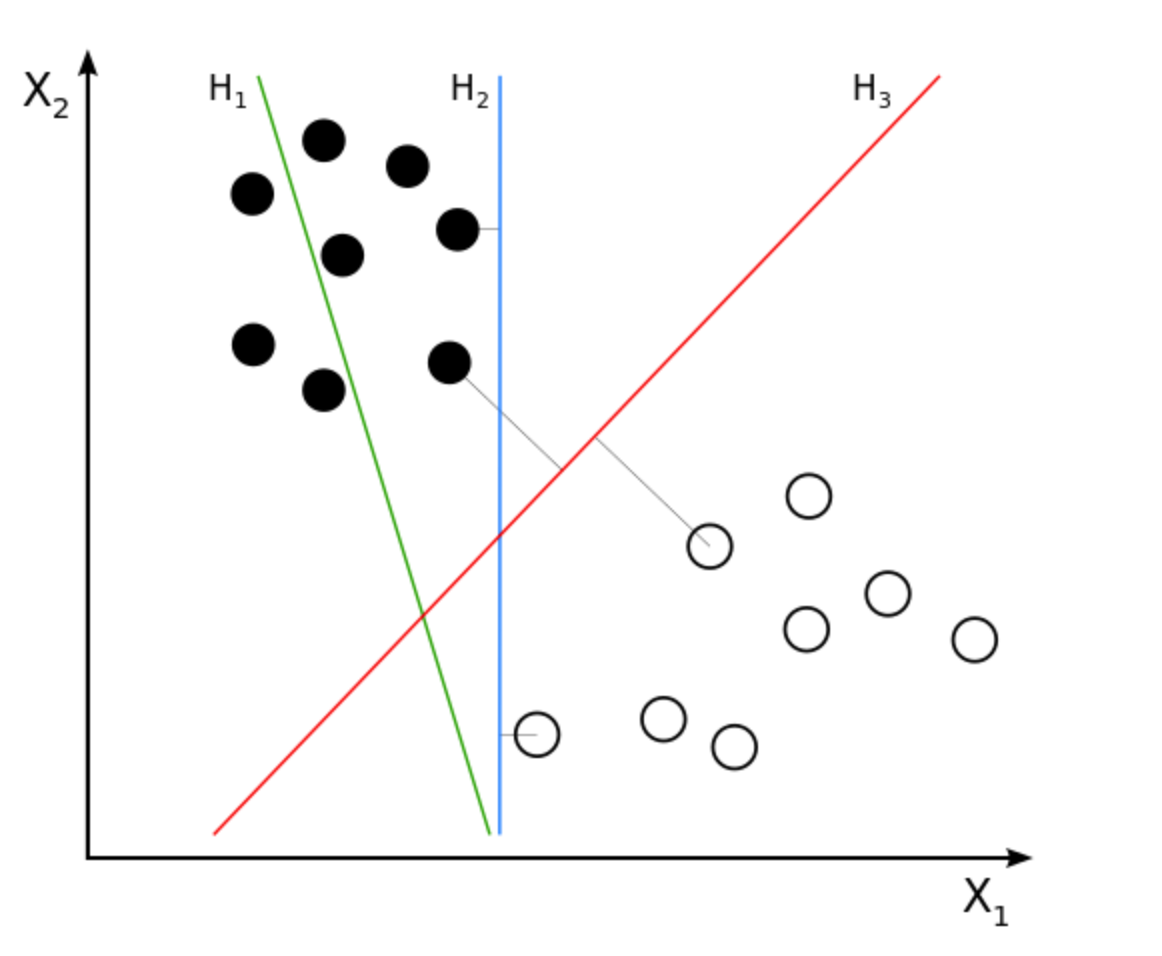
假设我们有一堆正负样本如图,我们想找一条线(一个超平面)去把这些点分开来。这条线当然是无穷条的,在图中我以H2 和 H3为例,H2和H3看起来都把正负样本分开了,但是我们的目标不是在训练集上取得好成绩吧,我们的目标还包括测试集(unseen data)。
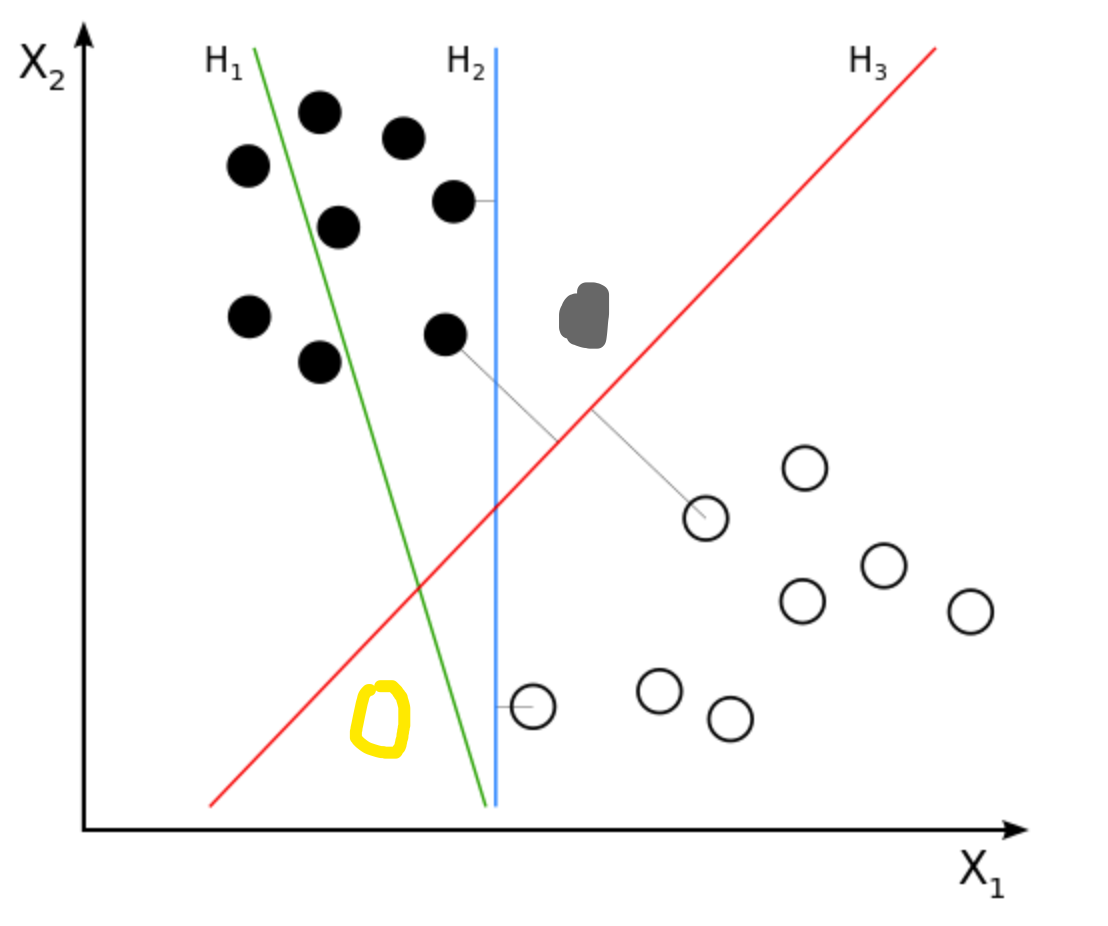
这时候我们给出了测试集(就是我新加上去的点),我们发现H2这条线完全分错了。而H3则分类的不错,粗略得来讲,H3距离正负样本的距离都很远,因此他的泛化能力很强。
至此我们明确了我们的任务,就是找到H3。那么很自然的,我们就产生了两个问题:
- 如果这样的超平面确实存在,如何寻找?
- 如果这样的超平面不存在,那么如何找到一个尽可能分开正负样本的超平面?