Information Retrieval的复习笔记,感觉最近忙到爆炸,春假了在图书馆发霉。真的爆炸!!
1. Text Processing
What is Bag of words? How to simplify calculation?
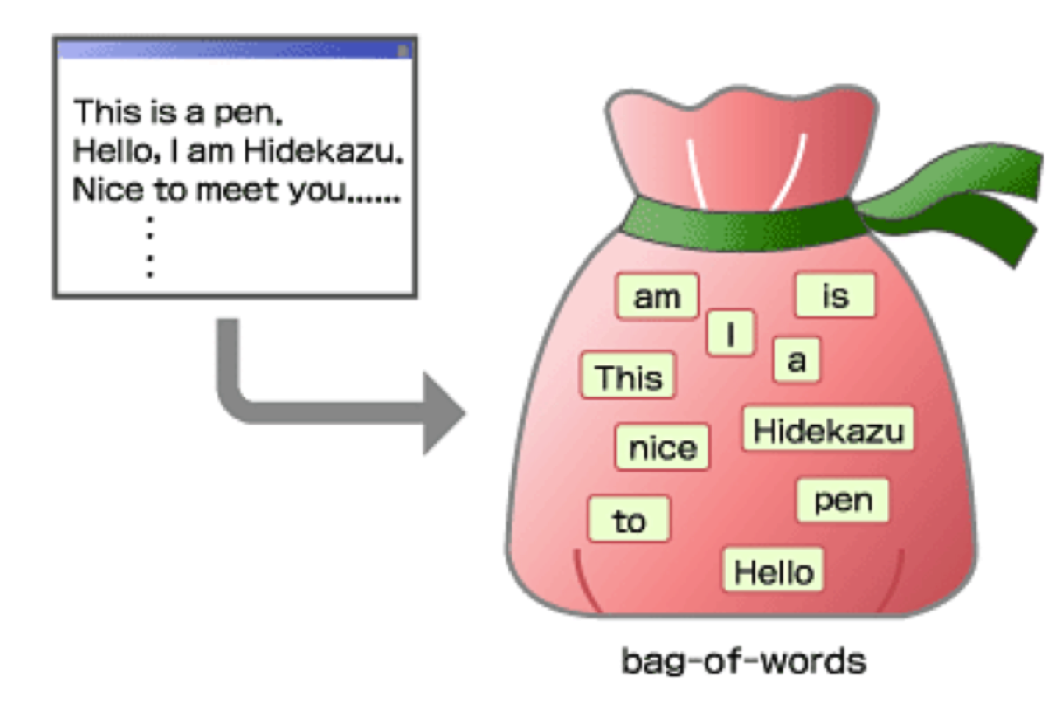
Bag of words is a collection of words appear in document. It assmume the word is independent with each other. Also it failed to recognize semantic relationship among words, it would not tell you synonyms words, hyponym and hypernym, homonyms. But we can tokenize each word unit for indexing, stemming.
Remove stop words
去除一些没用的词, the, a, an ….
Lemmatization
Reduce inflection/some derkvational variant forms to base form.
- Am,are,is -> be
- Car, car’s, car’s, cars’ -> car
works most on inflectional variants
合并一个单词的不同词形
Stemming
conflate morphological variants to their roots, called stems.
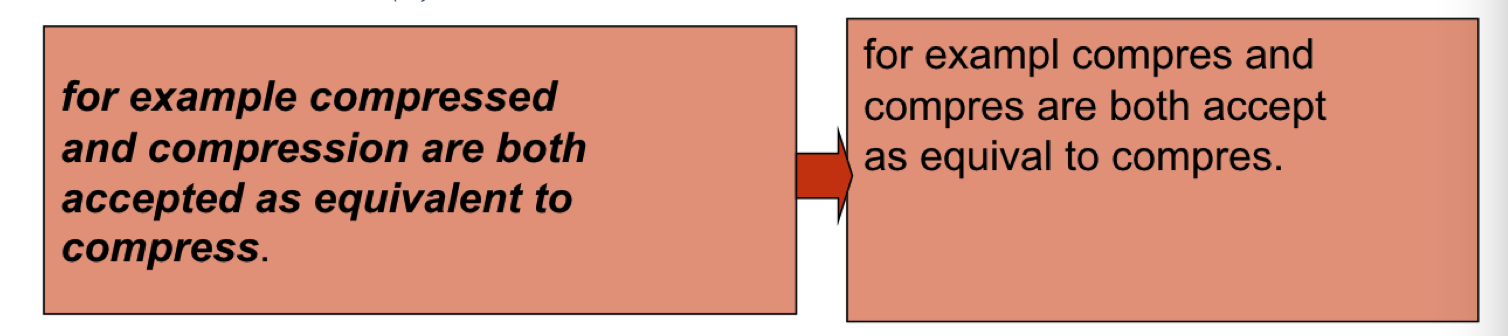
会去掉单词尾部的一些字母,合并形态上相似的词语,有同个词根的。
Works on derivational variants
Why stemming is better than lemmatization>?
English has many morphological variants in its language, so it is
important to recognize these variants are related to the same root words.
Stemming helps on that.
Stemming is more robust than lemmatization, and can handle more
complicated cases.
Why stem? why apply to both query and document processing?
2. Query Processing
执行和document一样的步骤
Index
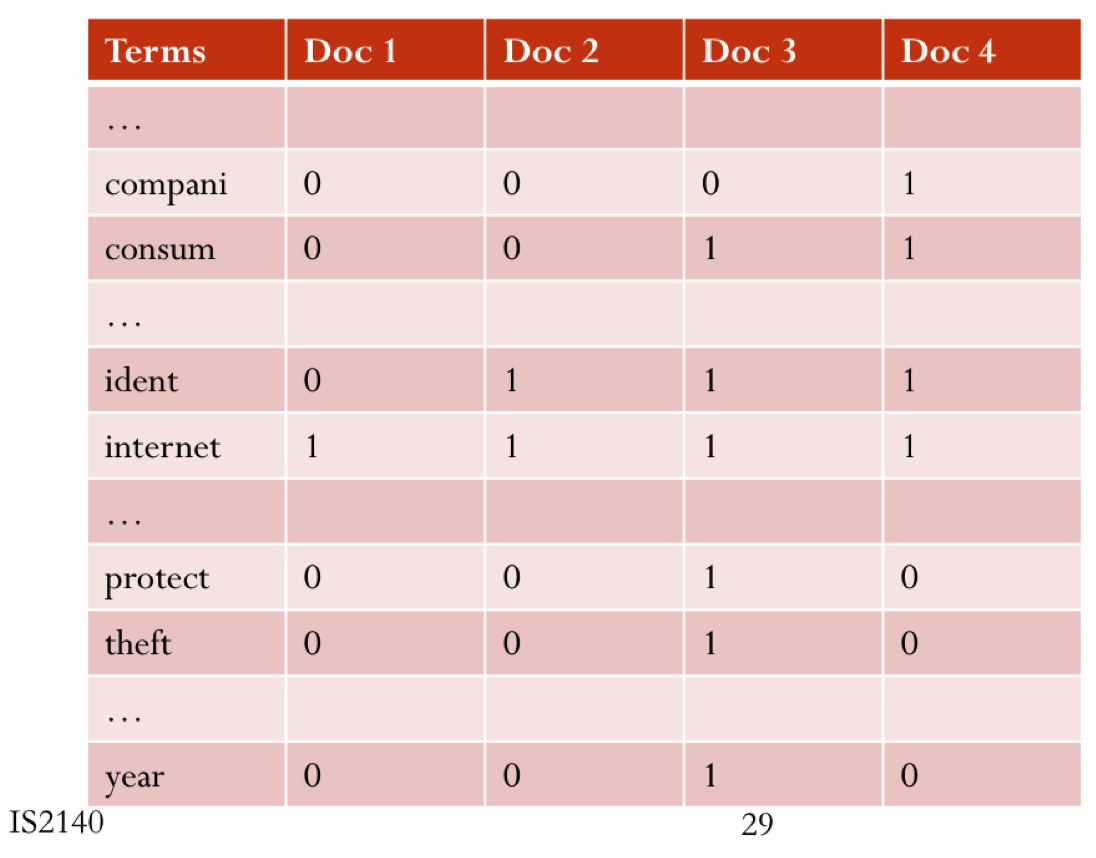
统计每个term在每个doc的frequency,构建矩阵。 很稀疏。
解决办法:构建post list
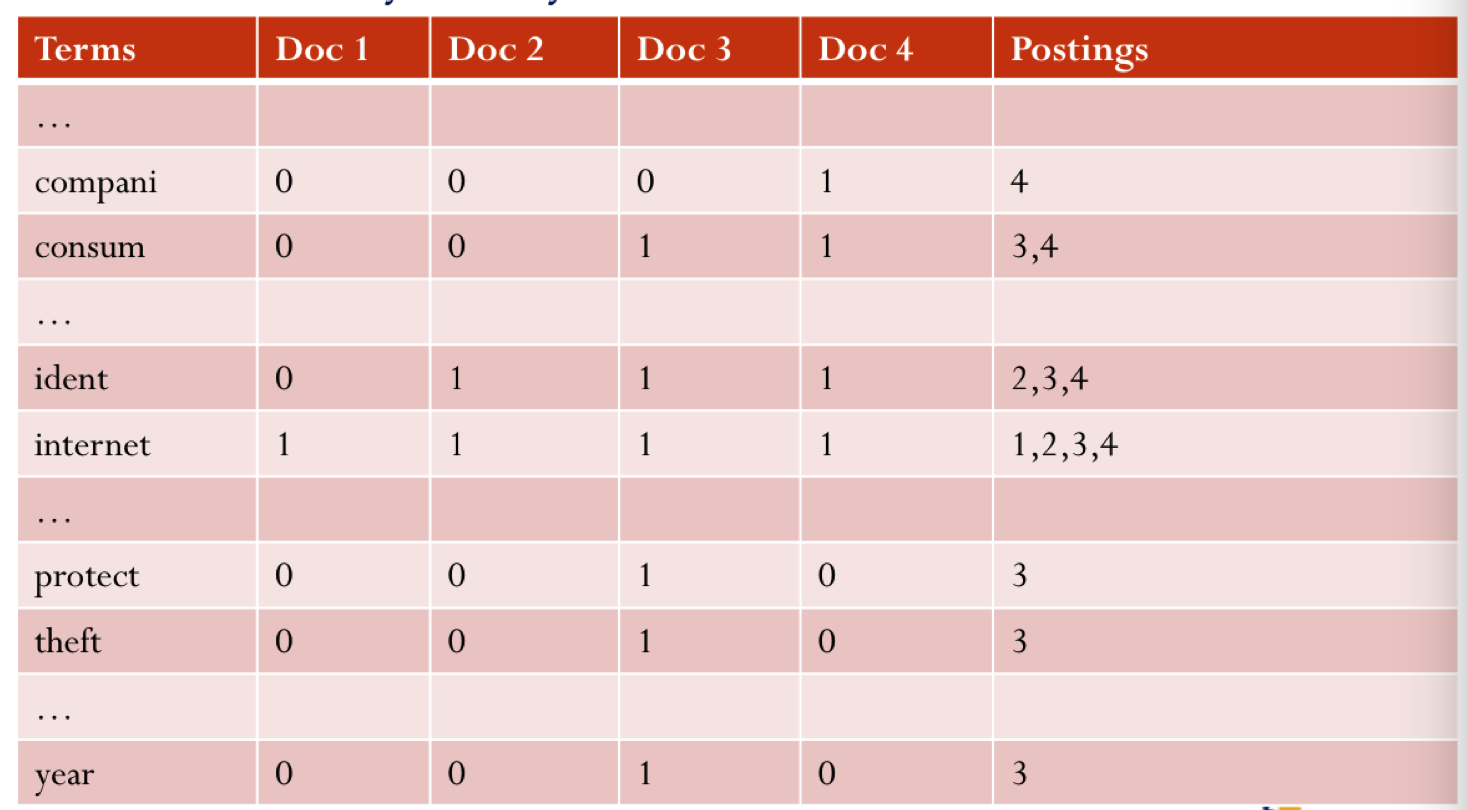
但是里面没用位置信息,也没有哪个doc的term frequency
postlist会很大,不能存放在ram里,这样会降低查询效率,因此要使用编码去压缩字典
Gamma code
length+offset
其中length由unary code组成(3 is 1110, 7 is 11111110)
Offset is binary, but first leading 1 is removed.
1110011(1110+011)
11111100101011110111
- 1111110 010101-> 1010101
- 1110 111 -> 1111
Boolean and Vector Space Model
Boolean Model:
use and, or, not to search document.
Vector Space Model
- replace relevance with ‘similarity’
- rank documents by their similarity with the query
- Treat the query as if it were a doucment
Treat documents as vectors, term as axes of the space, vocabulary size = |V|, we have |V| dimensional vector space
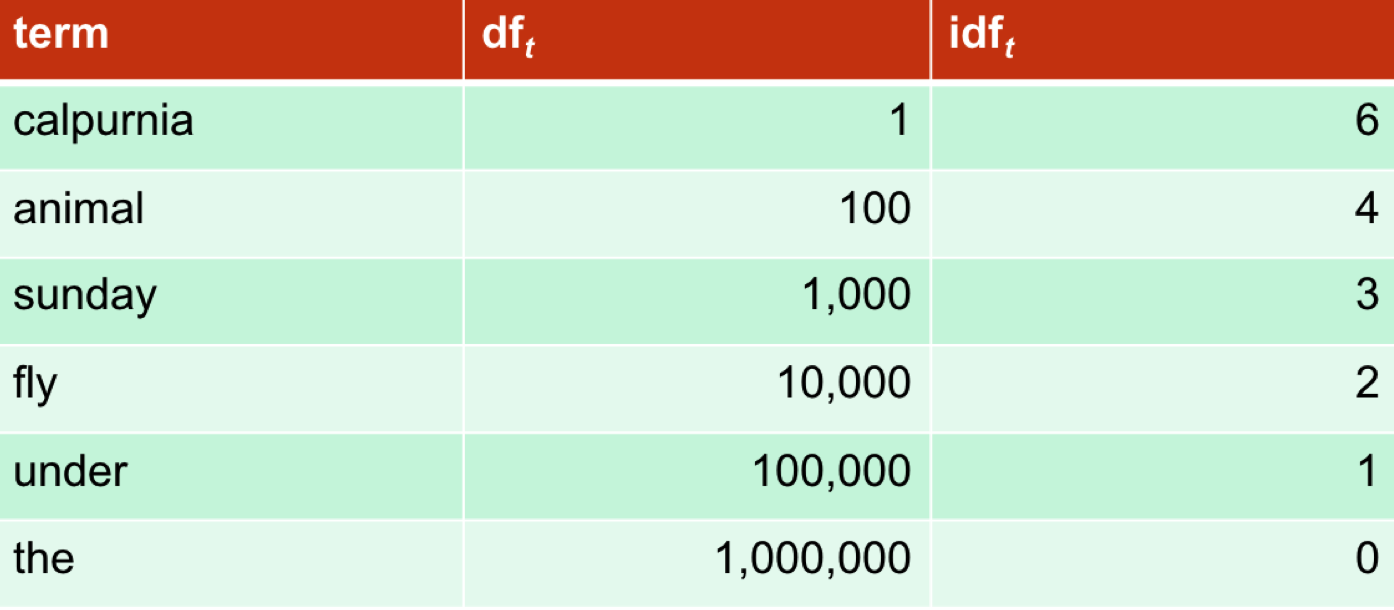
Tf-idf? why we need inverse document frequency?
Tf-idf weighting increases with the numberof occurs within a document and the rarity of the term in the collection. Thedocument length is to help normalization, especially when calculating cos ofvectors, avoid the distortion caused by size of documents.
log frequency weight of a tem t is:
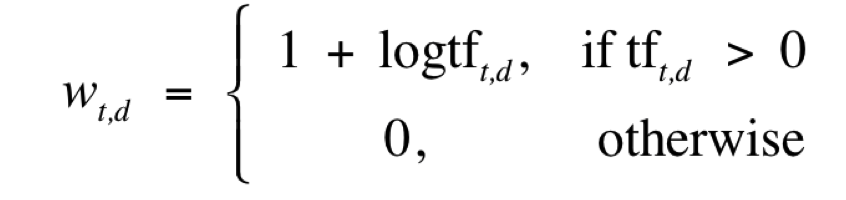
Idf:
tf-idf weight of a term:
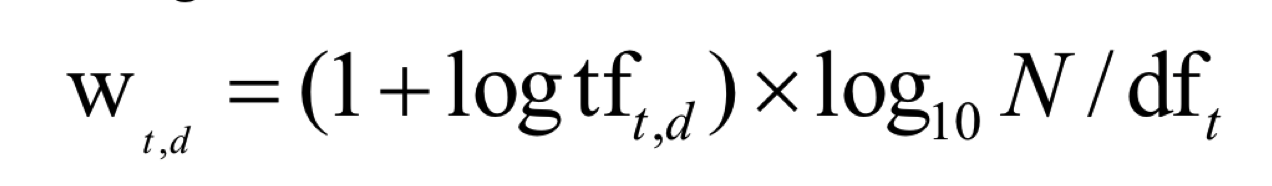
Language Model
differences between statistical language model and vector space model?
In vector space model, we build the term-document matrix and calculate the similarity base on those terms which we preprocessed. And in the statistical language model we count the frequency to calculate the probability of each document to get the rank list of retrieval results. Usually those queries will let the document get higher score and return in the higher rank of retrieval list. So, base on those kinds of model we can still get the document what we need.
Unigram LM
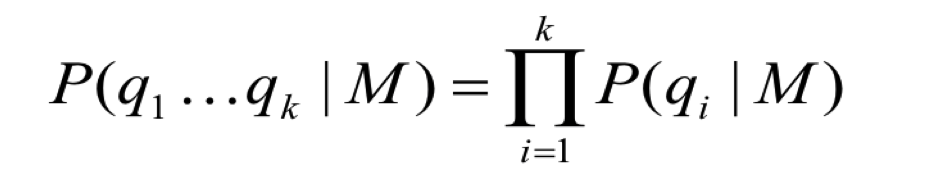
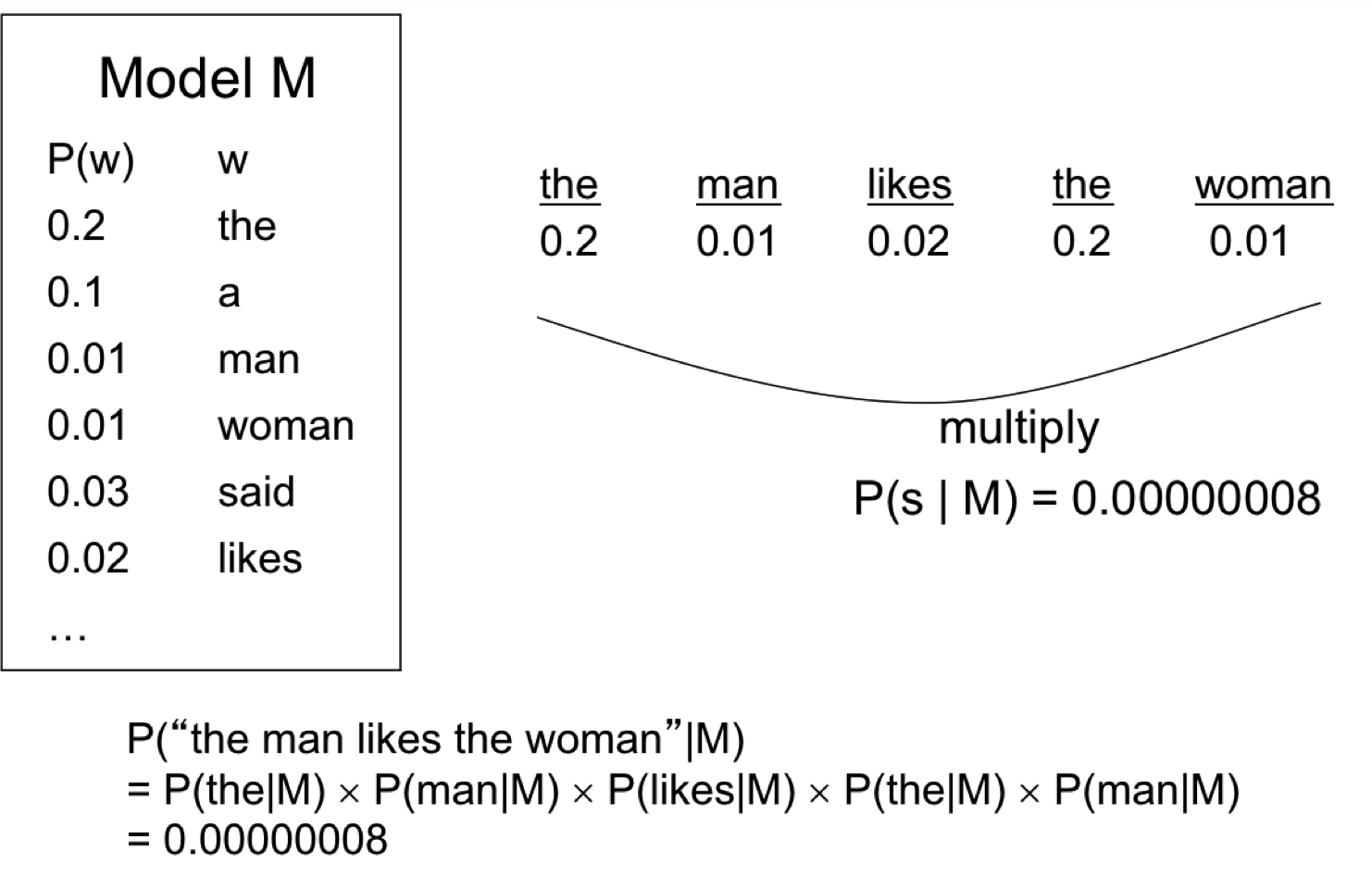
Query Likelihodd Language Model
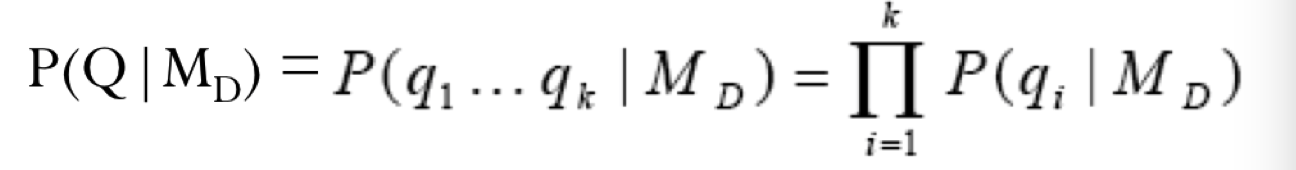
长度会造成很大影响,因此提出了以下模型
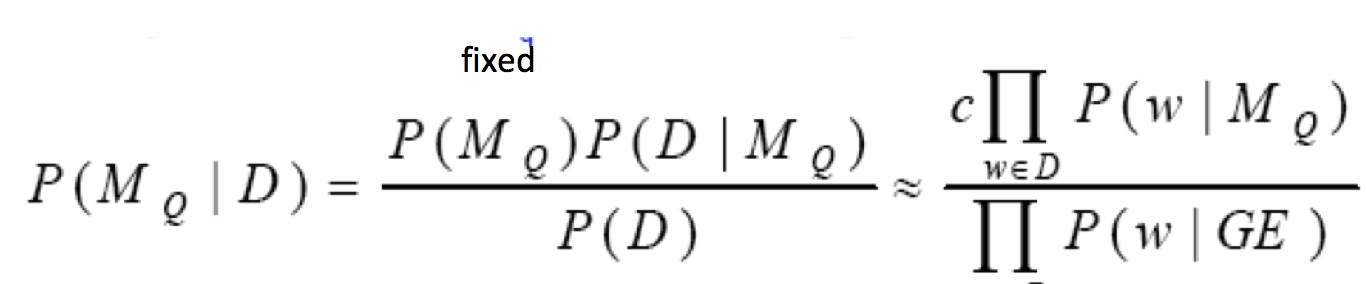
但是概率很快就变成0了,因此我们需要smooth!
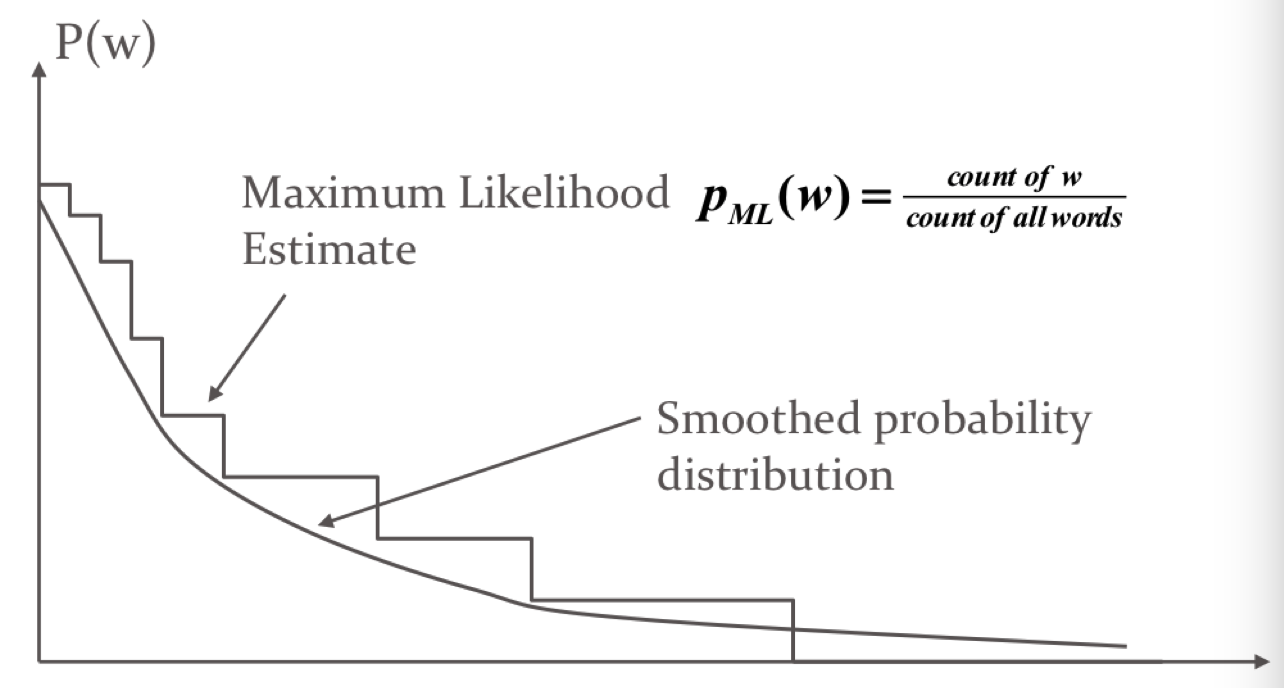
JM smooth
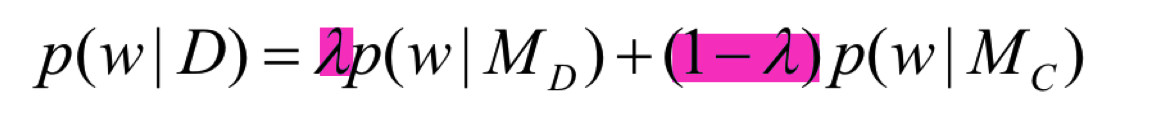
加入参数$\lambda$, 通常$\lambda = 0.8$。
Mix the probability from document to general collection
Dirichlet prior smoothing.
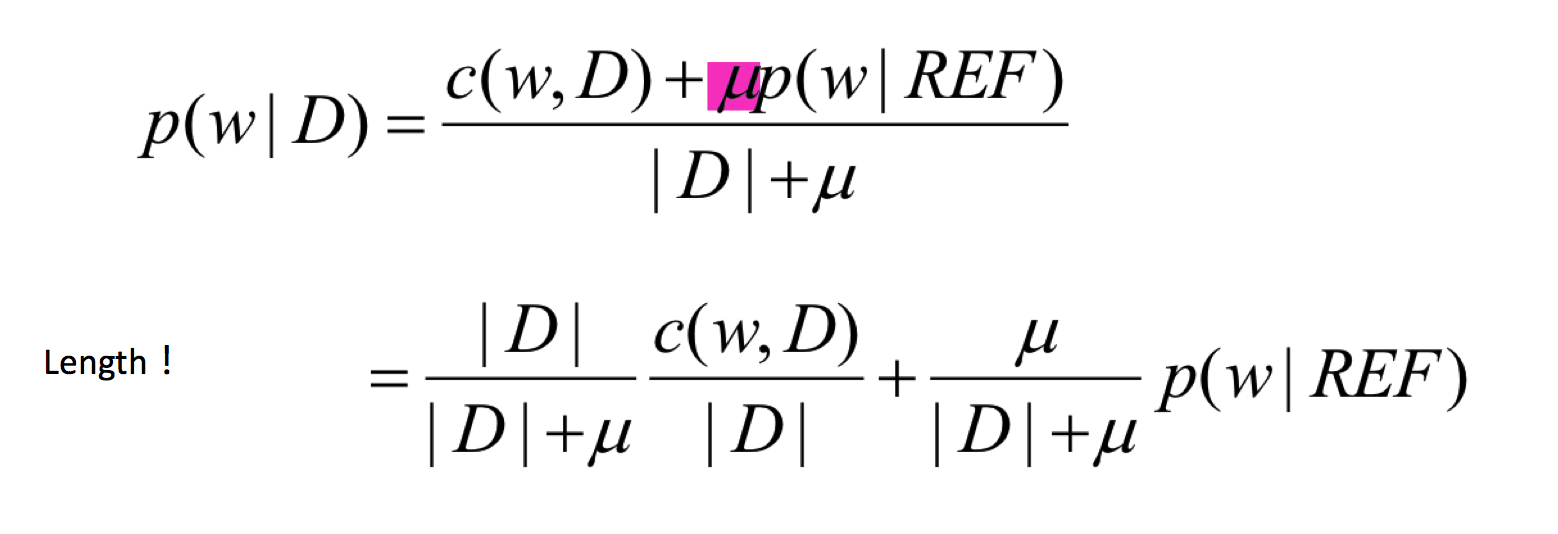
Evaluation
describe what is topical relevance, and discuss why it is the right relevance definition for Cranfield evaluation paradigm.
Topical relevance is a type of relevance that is related to the content of the document and is objective, which is the result of the match between a query and the document, ignoring the role of users.
The topical relevance is the right relevance definition for Cranfield evaluation paradigm because when we use topic as our search standard,we can use different kind of model to calculate the score of each document orget the rank list of document collection. So, we can base on the topical relevance to get the retrieval results which user need.
Precision, recall?
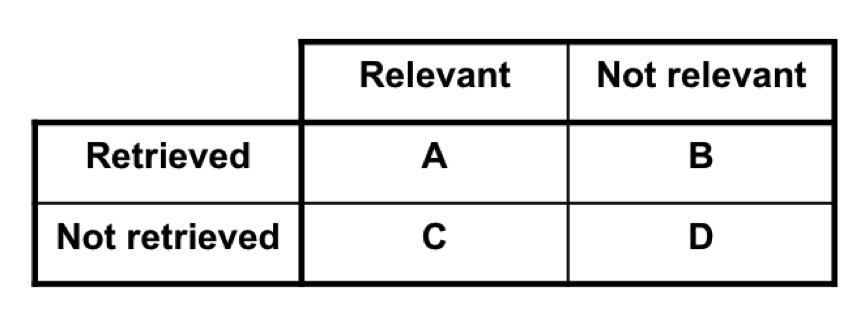
Precision = A / (A + B)
Recall = A / (A + C)
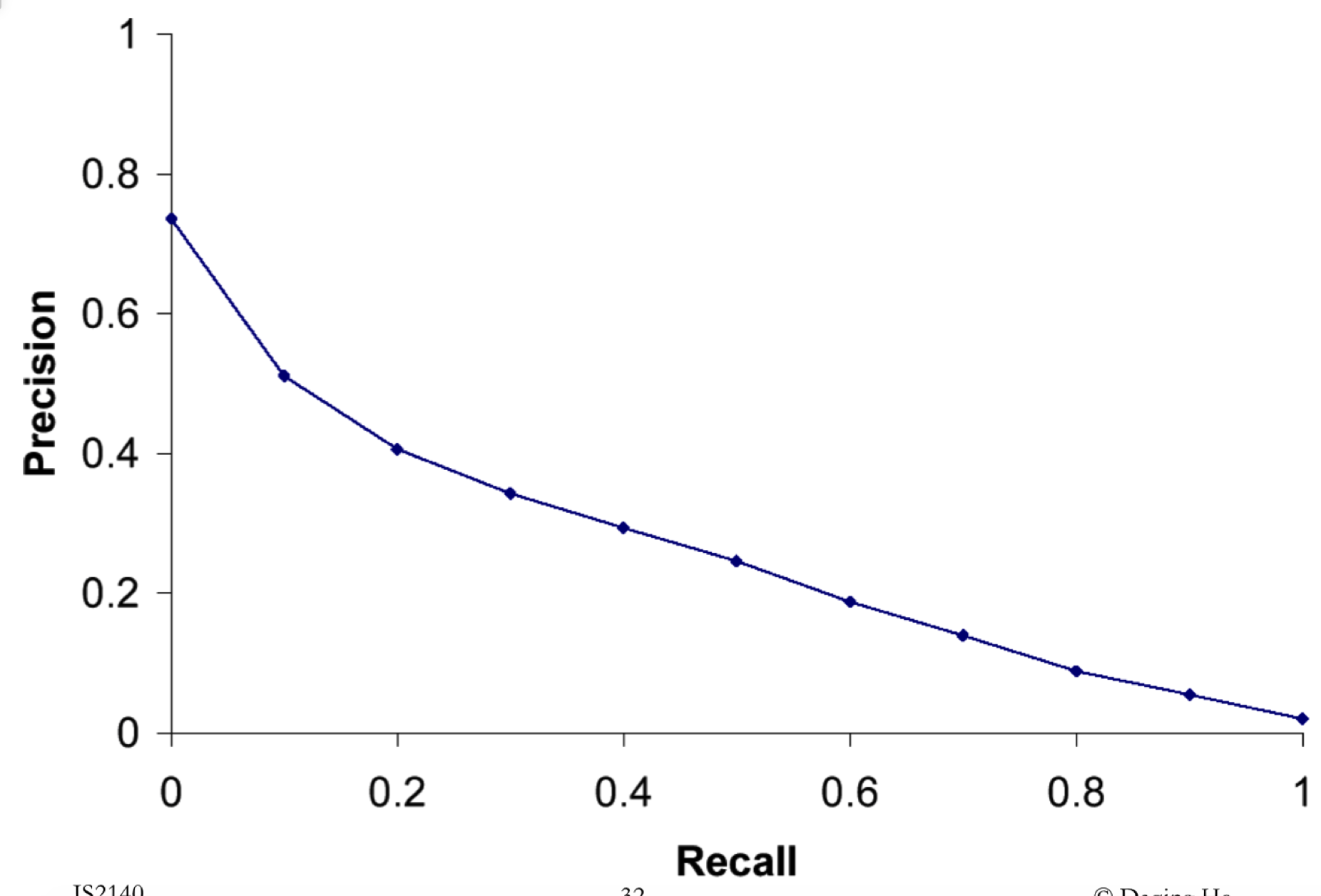
Trade off
describe what is precision, then discuss why we need to consider both precision and recall when evaluating information retrieval systems.
Precisionrepresent the percentage of the relevant document in the all retrieval results.So, the precision higher means that the retrieval accuracy is higher.
We need toconsider both precision and recall when evaluating information retrievalsystems, because it will base on different standard you set and get differentresults. Some system will more care about the recall because they need toretrieval all relevant document in their system. However, some system may justprefer to get the high percentage of the relevant documents in their results. So,we usually use the F-Measure to consider both precision and recall and use Betato trim the precision is more important or recall is more important.
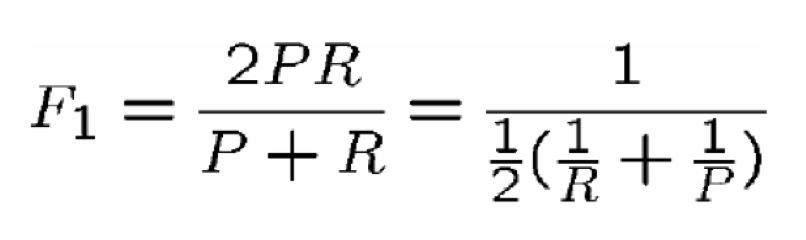
R-precision
R = |all relevant doc|

DCG
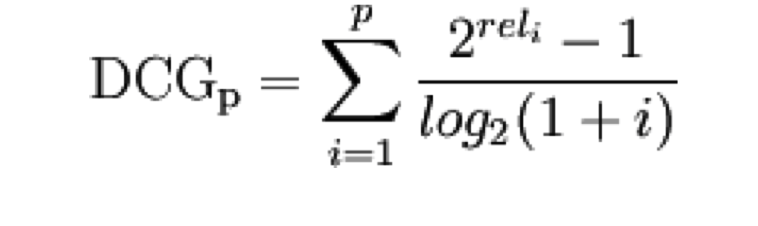
当文档有相关程度reli的时候,我们就有了dcg去衡量,越相关的应该放在越前面。
implicit Relevance Feedback, difference with pseudo relevance feedback?
- Explicit relevance feedback
- users explicitly mark relevant and irrelevant documents in the search reuslts.
- Implicit relevance feedback
- system attempts to infer user intentions based on observable behavior
- Blind relevance feedback pseudo relevance feedback
- Avoid obtain user explicit or implicit feedback information.
- use top returned N docs in the intial result
- assume all of them are relevant
pseudo problem
When we do the relevance feedback we need user to provide their feedback or help us to define some answer for building a better query. But in pseudo relevance feedback, we don’t ask the user to provide the feedback. What we do is to see the top N of first retrieval documents as the relevance to the user’s query and use those documents to build an advanced query to search in the system.
Rocchio
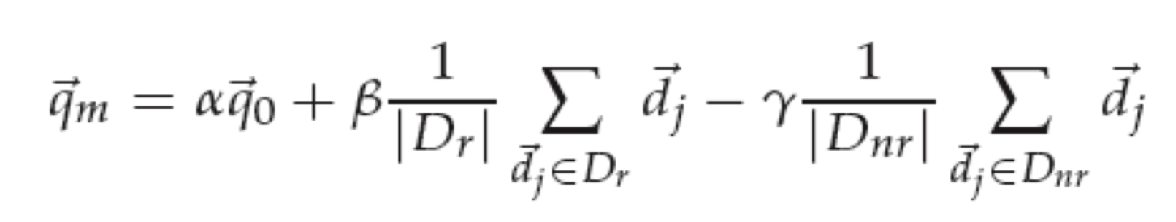
如何衡量ir system