简介:
最近学习了机器学习的算法基础,也实践过很多小数据的数据分析,因此对大数据的分析产生了兴趣,想部署一个spark集群去学习大数据,发现aws虽然免费但是挺坑的,只有1g memory。偶然了解到google cloud,听说google cloud给注册用户赠送有效期为一年的300刀抵用券,而且在google cloud上部署hadoop集群或者高性能机器都很方便。
jupyter notebook + pyspark: spark上提供了很多机器学习的算法,而且支持集群计算。加上jupyter notebook这种直观的可视化界面,更加方便。而且jupyter notebook作为一个web application,完全可以在google cloud上运行,将端口映射到本机后,用户则可以直接使用高性能集群上的jupyter notebook可以直接关注算法本身而不用去考虑集群的配置,可以说是数据分析的很好的工具了。
Google cloud网页配置
Google cloud基于google cloud sdk,可以下载cloud sdk在本机上使用命令gcloud,同时google cloud也提供了网页版的shell,也很方便。
推荐大家先在网页上注册google cloud,填写支付信息(必须有可以支付美元的信用卡)然后按照流程去走一遍(创建自己的instance,部署一个app,看谷歌炫技)。过程中会创建自己的project,记下id。
下载google cloud sdk
https://cloud.google.com/sdk/downloads
按照网页上的步骤安装就可以了,十分方便。安装成功会让你登陆谷歌账号和配置一些instance的环境。
配置集群和jupyter
这一步是在本机上执行
然后就可以配置你的hadoop cluster了。我推荐在本地的terminal里配置。输入如下命令(创建cluster并配置安装jupyter):
1 | gcloud dataproc clusters create cluster-name \ |
其中\是换行标志,— 后面跟的是属性,在这里我标注了使用的Master和salve的型号,如果不标注则无法运行,(因为默认的配置会使你的钱包溢出了)。这里配置好了待会也可以去网页上更改配置,因为这里是500g的硬盘,一般用不了这么大。
1 | gs://dataproc-initialization-actions/jupyter/jupyter.sh |
gs:github shell,执行GitHub的shell,这是按照jupyter、anaconda和spark的脚本。
Pip版本升级
这一步是在网页上的Master的shell里执行。(master的ssh)
首先要更改脚本装的conda的权限
1 | sudo su |
然后再切换回自己的用户
1 | exit |
pip是python里包下载工具,最好升级一下不然会出现很多怪错误。
1 | conda update pip |
连接jupyter
这一步确实有很多坑啊,参考了很多命令才得以使用。
防火墙设置
可以直接在google cloud的搜索栏里搜firewall rules。
再去里面创建firewall rules。填写如下配置
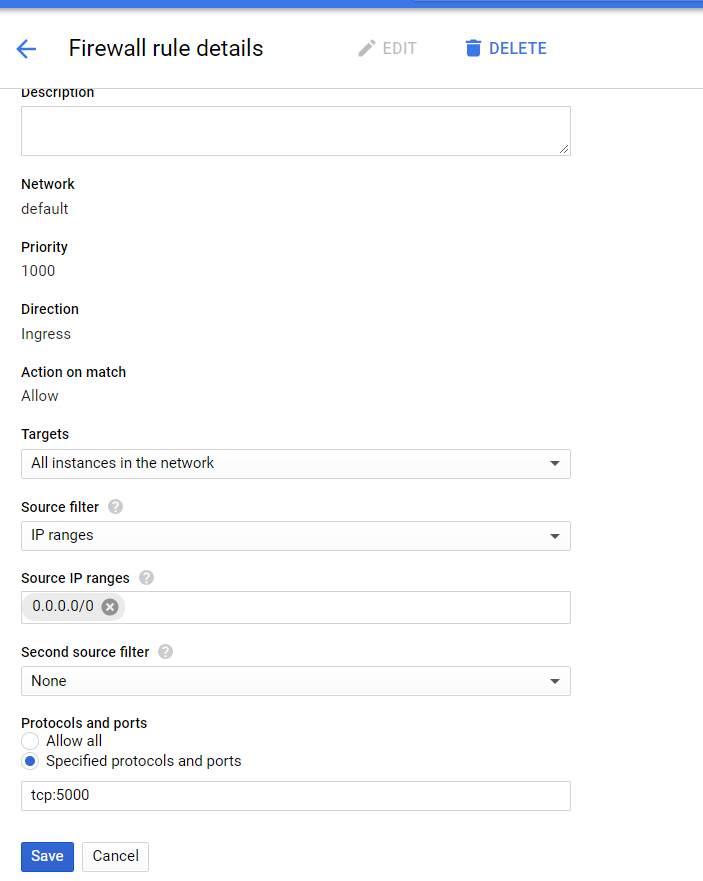
其中的tcp:5000是声明通过ipv6连接cluster,同时这个5000也是我们启动jupyter的端口,接下来本机要通过映射去得到这个5000端口。
jupyter的启动
这一步是在网页上的Master后ssh的terminal里执行。
对于jupyter的一些概念,在哪个路径下启动jupyter notebook,打开的默认位置就是那个路径。有点类似于先选定project的位置,再打开编译器。
我们最好不要直接在根目录下启动jupyter,会产生一些怪问题,最好是找到自己用户的路径然后自己mkdir一个路径去做jupyter,5000是刚设置的端口。
1 | jupyter-notebook --no-browser --port=5000 |
会产生一个token给你,
本机terminal配置
本地映射服务器端口
这一步是在本机terminal执行
在这一步确实会有很多幺蛾子。先说我的方法吧:
1 | gcloud compute ssh <master> -- -L <your port>:127.0.0.1:<jupyter port> -N -n <master> |
example
我是映射到了本机的1024端口,只要那里没有端口占用就行了。
1 | gcloud compute ssh tianchi-m -- -L 1024:127.0.0.1:5001 -N -n tianchi-m |
记得Master后面都跟一个-m的,也就是clustername-m。
然后登陆localhost:1024就可以看见我们的jupyter了。第一次登陆一般要输入token。在网页上的terminal里有,复制过来输入就好。
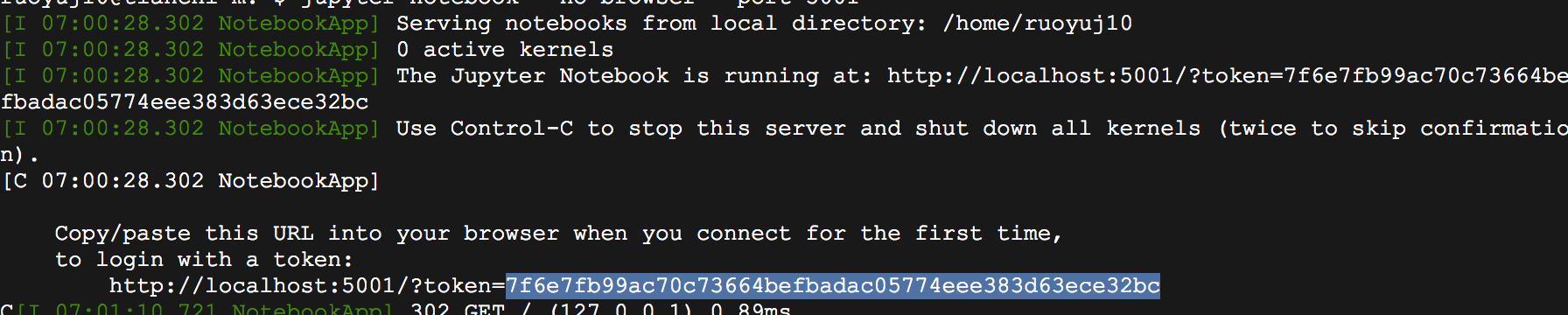
成功启动:

官方的办法:
1 | gcloud compute ssh cluster-name-m -- -L 1080:cluster-name-m:8088 -N -n |
SSH Túnel
还有一种方法是开一个ssh tunel, 再启动有代理的chrome,这样的好处是可以看全部的webui。包括jupyter,spark,hadoop。
开启Tunel
规范:
1 | gcloud compute ssh --zone=master-host-zone master-host-name -- \ |
我的
1 | gcloud compute ssh --zone=us-east1-c tianchi-m -- \ |
设置chrome的代理
1 | Google Chrome executable path \ |
-proxy-server="socks5://localhost:1080"tells Chrome to send allhttp://andhttps://URL requests through the SOCKS proxy server localhost:1080, using version 5 of the SOCKS protocol. Hostnames for these URLs are resolved by the proxy server, not locally by Chrome.--host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost"prevents Chrome from sending any DNS requests over the network.--user-data-dir=/tmp/hadoop-master-nameforces Chrome to open a new window that is not tied to an existing Chrome session. Without this flag, Chrome may open a new window attached to an existing Chrome session, ignoring your--proxy-serversetting. The value set for--user-data-dircan be any nonexistent path.
Chrome path:
| Operating System | Google Chrome Executable Path |
|---|---|
| Mac OS X | /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome |
| Linux | /usr/bin/google-chrome |
| Windows | C:\Program Files (x86)\Google\Chrome\Application\chrome.exe |
我的
1 | /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome \ --proxy-server="socks5://localhost:1080" \ |
连接成功
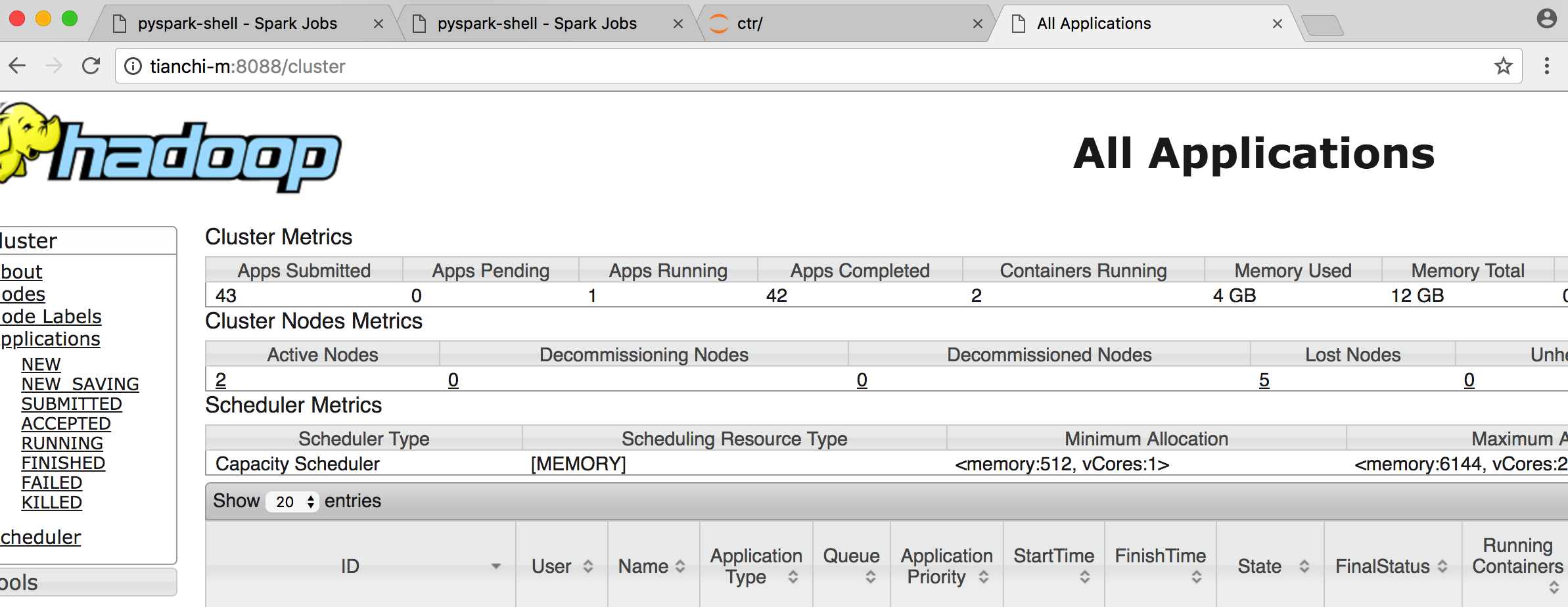
注:在连接jupyter的时候,主机名就不是tianchi-m了,是localhost。而别的webui都是你的cluster master name。
别的连接/参考方法链接:
https://cloud.google.com/dataproc/docs/concepts/accessing/cluster-web-interfaces