GFS 阅读笔记
GFS这篇paper可以说十分经典,在云计算课程上,老师要求我们去阅读这篇论文,由于GFS的篇幅很长、涵盖的面很多,我参考了网上许多的阅读笔记和原文,做了如下的记录和总结。
1. GFS是什么?
GFS(Google File System)是一个大规模,具有高拓展性(scalable)的分布式系统,分布式集群是建立在大量的普通硬件上的,有很强的fault tolerance,能够响应大量的客户端。
GFS设计需求
- 建立在大量的便宜硬件上,因此必须有极强的监控、监测、恢复、容错机制
- 存储大数据(Multi-GB)
- read操作:
- 针对大文件, 流式读取连续文件. (100+KBs, 1MB or more)
- 针对小文件, 随机在不同的位置读取. (Few KBs)
- 大的顺序写入多, 但是数据更改少.
- 高并发性(超多生产者, 超多消费者(同时从不同节点读文件))
- 保证高带宽(bandwidth)而非低延迟(大量用户注重读写速度而非响应时间)
GFS API
Create, delete, open, close, read, write,record append(追加写), snapshot(文件快照)
2. GFS架构
Single master, many chunkservers and clients.
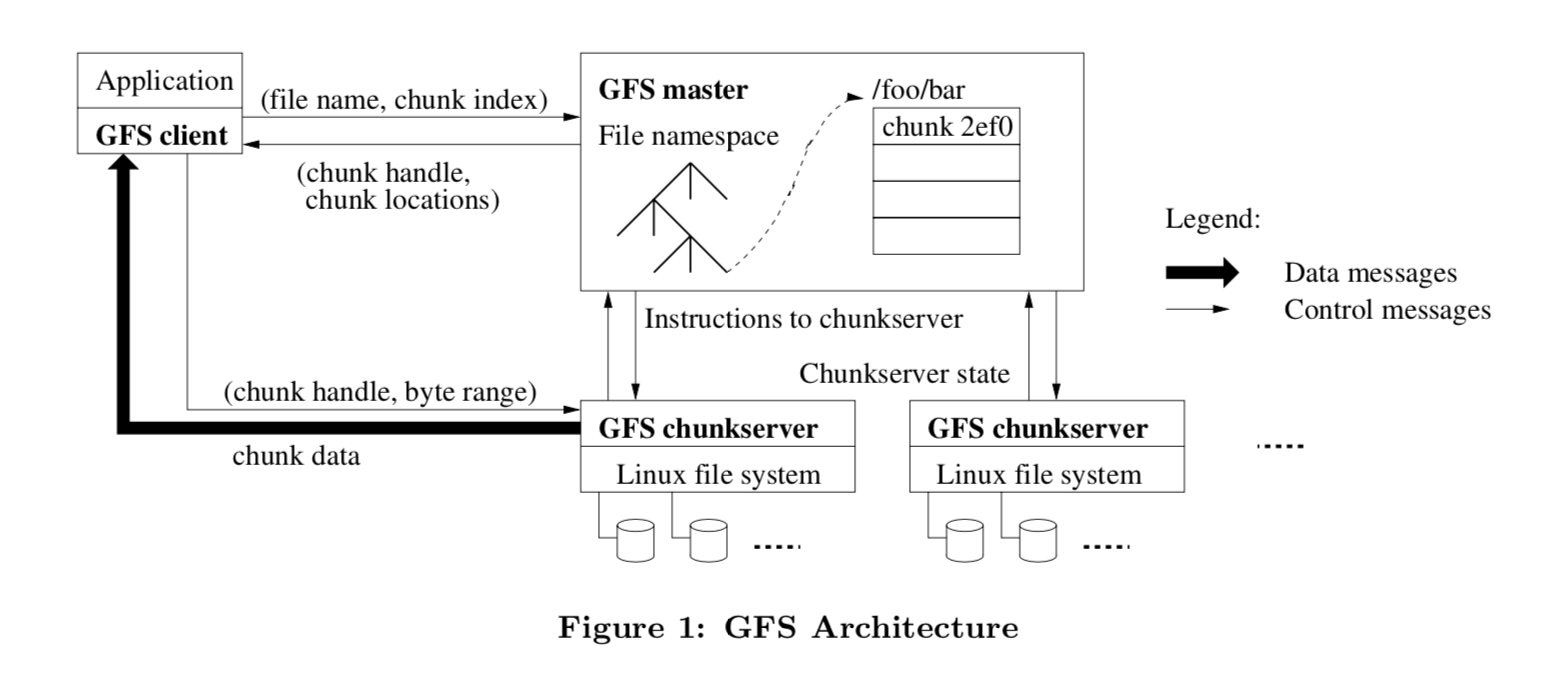
GFS特点概述
- 文件按fix-size chunk存储, 每个chunk在创建时有一个不可改变的64位的标识符, 一个chunk有三个备份.
- Master存储所有的 metadata, 其包括namespace, access control, 文件与chunk的mapping, chunk的位置.
- Master管理chunk的lease, gc, migration. Master通过HeatBeat来向节点传递信息和节点的状态检查.
- client向Master请求metadata操作chunk server
- client和server都不缓存文件数据(保证数据一致性). 但client会缓存metadata
Single Master
GFS为了简化设计, 在整个系统中只有一个Master, 为保证性能Master也不提供读写操作给client, 只通知在哪里读取。
e.g. Interaction for a simple read (Figure 1)
- client将应用程序请求的文件名、大小转换成chunk index, 然后将其擦混送给Master.
- Master返回chunk handle和备份位置信息
- Client将文件名和chunk index作为key, 返回信息作为value.
- Client向备份之一的chunk server(一般是最近的)发送请求(chunk index, byte range)
- 在lease期限内, client都可以与chunkserver通信, 过期后要再向Master请求.(lease确实很厉害啊, 在后面会详细叙述)
Chunk size
64MB >> 一般文件系统块大小
Pros:
- 减少client与Master交互(因为存在大量的连续存储, 因此大的块当然可以记录更多的信息)
- client 可以在一个块上执行更多的操作, 减少了网络压力
- 减少了存储在Master上的Metadata的大小,这允许将Metadata存储在内存里
Cons:
Hot Spot
- 由于一个chunk可以存更多的小文件, 他的操作频率会变高,这会给chunk很大的压力(但是在实际中影响不大)
- 在批处理系统(batch-queue System)中, 一个chunk上的可执行文件要被许多client执行, overload啦. (解决办法是多加几个备份, 允许client去读别的client的文件)
Metadata
元数据存储了三类信息:
- 文件和chunk的命名空间
- 文件与chunk的映射关系
- 备份的位置
我们知道metadata存储在内存里, 有很多的有点, 但是会不会受限于内存大小呢?实际上不会的, 每个metadata少于64kb又能记录64MB的chunk信息, 然后内存又便宜(谷歌部署不了大量的高性能服务器,还升级不了内存?)
chunk的位置
chunk的位置信息是定期通过heartbeat更新的, 这样减少了与chunkserver和Master时刻通信的代价。
当然每个chunkserver都有一个final word, 记录那些他有哪些chunk, 而哪些chunk又不在了.
Operation Log
我们都知道log这种东西在任何系统里都是十分重要的, 在GFS也是,
- 因为他是在gfs里唯一记录了所有metadata所有的信息的东西.
- 而且记录了操作的时间线, 这在回复过程中是十分关键的.
checkpoint记录在一个类似B-Tree的结果里
一致性模型
这部分很重要
如何保证:文件命名空间的变化是原子性的(atomic), 命名空间锁.
GFS定义的概念:
- 如果所有客户端从任意备份读取相同文件, 得到相同结果, 则改文件是一致的
- defined: 如果一个文件区域在经过一系列操作之后依旧是一只的,并且所有客户端完全知道操作过程,。
- 如果一个操作没有被其他并发进程干扰, 那文件区域是defined的.
- 如果所有客户端没有知道一个并发操作的过程,但是该并发操作的结果是一致的,那么该文件区域是undefined的.
- 失败的并发操作不用说,是不一致的,操作的文件区域也是undefined的.
造成数据的改变:
write and record append(no overwrite)
GFS保证一致性的办法:
在所有备份机上执行相同的操作顺序.
使用chunk version来监测任何过期的备份, 过期的备份就被gc了
但如果不小心读取到了过期的呢?比如因为信息没被更新, 没事, 由于只有追加写, 大家差不多都一样麦。当收到Master的信息的时候,再去新的chunk也不迟
通过handshake来检查宕机的服务器(和heartbeat有什么不同呢?)
通过checksum来保证文件完整性。
3. 系统交互
在这一部分, 我们来看GFS为了保证让Master介入最少, 如何去设计client, Master和 chunkservers 之间交互, 以及数据修改, 原子操作和快照.
Lease and Mutation order
定义:
Primary(主席): Master(中央)把lease发给replica中的一个(被钦定), 然后改node就要开始选定一个执行顺序,让别的replicas一起执行. 每个lease60秒的有效期(time out),
常见问题:
Q: 如果Master联系不到primary怎么办?
A: 在现有协议结束后,Master会钦定一个新的replica.
Q: 要是Master要停止这个操作怎么办?
A: 提前解约这个lease.
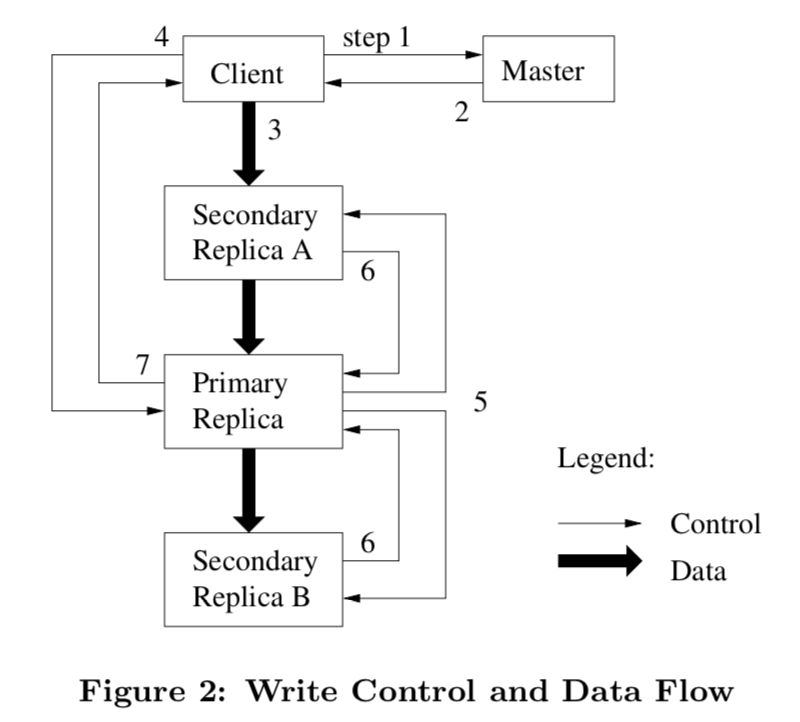
过程解读:
- Client向Master请求持有的lease的chunk(primary replica)位置和其他replicas的位置. 如果没有主席, Master就钦定一个.
- Master告知client主席的信息和replica的信息,然后client将信息缓存.(当primary无法通信或者primary replica没有lease了,client才会向Master再次请求)
- client会把数据发送到所有的replicas,大家存在LRU缓存里.
- 在大家都收到数据之后,client会向primary发送写请求,primary给mutation分配序号(mutation可能来自不同的client),然后执行
- primary发送给大家序号,大家也按序号执行.
- 告诉主席做完了
- 主席回复client完成的状态或者错误,client的error handler会重试失败的mutation.
Data Flow
设计目标:
- 充分利用网络带宽(network bandwidth)
- 避免网络瓶颈和高延迟
- 减少数据流动的延迟
设计方案:
- 数据在chunkserver中线性流动(而非类似树的结构). 每个机器都在用自己的全部带宽与另外一个机器通信.
- 每个机器会把数据发送到还没收到数据且离自己最近的机器中(距离通过ip地址计算)
- 通过TCP连接将数据传输流水线化(pipelining),之所以如此有效是因为GFS使用全双工的交换网络(switched network with full-duplex links)
Snapshot
GFS通过snapshot来瞬间创建一个文件的备份或者一个目录树的备份, 应用了copy-on-write(在没有更改的时候,只用指针指向同样的文件)
当Master收到snapshot操作请求后:
- 废除所有lease,暂停所有写操作.
- Master记录所有操作,记录写入磁盘.
- Master将源文件和目录树的metadata进行复制,这样之前的记录和当前内存中所保存的状态就对应起来了,新建的snapshot和源文件指向的会是同一个chunk
4. Master职责
- 执行所有关于namespace的操作
- 管理chunk replicas:
- 做出chunk, replica放置决定
- 创建chunk, replica
- 协调各种活动, 保证chunk完全复制
- 负载均衡
- 回收闲置空间
管理namespace
就是用读写锁来保证顺序执行。
放置replicas
- 最大化数据可靠性以及可用性
- 最大化带宽的利益
要考虑到机架(rack)间的问题,将数据存放到不同的机架上,当一个机架宕机之后,别的机架还可以用.
这样对于一个chunk,可以利用多个机架的带宽,对于写的竞争,由于有好几个机架要去写,这样就达成了一个tradeoff!
创建replica
创建的三个情况:
- 创建新的chunk
- 重新备份
- 重新负载均衡
如何选择放到哪个机器?放置规则
- 优先利用磁盘利用率低的chunkserver.
- 限制每个chunkserver的”recent” creations, 因为创建要写,而大量写会造成traffic, 降低效率, 这是我们不希望看见的.
- 跨机架进行放置
当有多个chunk需要备份,要考虑优先级的问题:
- 基于replication goal: 可用备份少的先.
- 活着的比最近删除的先.
- 阻塞client过程优先
决定备份哪个之后, clone可用chunk到目标位置(遵循放置规则)
Garbage Collection
在GFS里,如果文件删除之后,GFS不会马上对其进行回收,而是要等待垃圾回收机制对其空间进行释放.这感觉是GFS的一个骚想法.为什么要这么做呢?在后面给出了部分的理由,看起来还是十分合理有效,开拓思路的.
GFS删除文件的策略:
- 记录删除操作,将此文件命名为hidden+时间戳.
- Master定期进行扫描,把隐藏了一段时间的空间回收, GFS设置为三天(这会产生问题,在后文会陈述)
- 在此期间,GFS可以对这个空间进行恢复, 改一个名字就好.
- 同时GC还会找到孤儿chunk(没有文件用到的非空chunk),然后清理该chunk的metadata.(比如创建一半失败了)
- 通过与chunkserver的心跳信息,每一个chunkserver会返回他有的chunk的子集,然后Master就会告诉chunkserver哪些是metadata都没有的.chunkserver就会对其进行删除(比如删除一半失败了)
讨论:
分布式系统的删和回收是很复杂的, 但在GFS里, 我们有replica的mapping. 这就省了不少事.
pros:
- 由于出错是很常见的, 这样的gc机制省了master不少的事情.
- 把空间回收和日常的handshakes结合起来, 分摊了开销, 而且这只是在master不忙的时候做, 优先级是低于回复client. 相比于删除GFS还有更重要的事情.
- 避免了意外删除、无法重现的删除的情况.
cons:
- 无法很好的去响应user对于空间的调整, 比如没什么空间了, 想删点东西, 但是发现删了没用.
- 有些程序删除和创建很频繁, 这导致他们没法马上使用他们删除的文件空间.
解决办法:
缩短删除时间, 允许读者自己定义. 例如一些目录下的就没有备份, 迅速删除, 释放空间.
过期replica监测
过期原因: chunkserver宕机, mutation丢失.
监测办法: 赋予chunk version number.
当Master给出新的lease的时候,会增加版本号并通知replicas去更新版本号, Master和replicas都会记录新版本号.
- 如果这是有一个replica不可用了, 那他的版本号自然就不好更新, 在chunkserver重启或者向Master报告的时候, Master就知道你过期了, 并用GC回收
- 如果是Master版本号落后, Master会更新自己的版本号.
5. 高可用性
在上百个GFS服务器里, 有些可能随时会不可用. GFS有两个策略: fast recovery和 replication
Fast Recovery
不管是什么原因导致的宕机, 马上重启. GFS甚至不会去管是不是异常宕机.
Chunk Replication
前面说过了
Master Replication
虽然只有一个Master, 但是Master的log和checkpoint还是存储在多个机器上.
一个mutation只有在Master和他的备份们都记录了之后才被视作完成.
当Master宕机之后, 可以用他的备份去重启一个Master. 但是client怎么知道你是新Master呢? 首先新老Master的名字是一样的, 要改的只不过是DNS而已.
由于新Master只是shadow Master 不是热备份的镜像Master, 因此他们只提供读的权限!
后面就是性能测试了, 就没有再看下去. 吐槽一下这论文实在太夸张了.